diff --git a/README.md b/README.md
index 5863556..43f0e3d 100644
--- a/README.md
+++ b/README.md
@@ -469,6 +469,21 @@ jupyter notebook examples/an_awesome_example.ipynb
| CLI Tips & Tricks |
Use FiftyOne's Command Line Interface to expedite your workflows |
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+ |
+ zero_shot_instance_segmentation |
+ Combine zero-shot detection plus segmentation and tracking with OWL-ViT, SAM, and FiftyOne |
+
## Contributing
diff --git a/examples/zero_shot_instance_segmentation.ipynb b/examples/zero_shot_instance_segmentation.ipynb
new file mode 100644
index 0000000..0b7064f
--- /dev/null
+++ b/examples/zero_shot_instance_segmentation.ipynb
@@ -0,0 +1,441 @@
+{
+ "cells": [
+ {
+ "attachments": {},
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "\n",
+ "\n",
+ " \n",
+ " \n",
+ "  \n",
+ " Try in Google Colab\n",
+ " \n",
+ " \n",
+ " Try in Google Colab\n",
+ " \n",
+ " | \n",
+ " \n",
+ " \n",
+ "  \n",
+ " Share via nbviewer\n",
+ " \n",
+ " \n",
+ " Share via nbviewer\n",
+ " \n",
+ " | \n",
+ " \n",
+ " \n",
+ "  \n",
+ " View on GitHub\n",
+ " \n",
+ " \n",
+ " View on GitHub\n",
+ " \n",
+ " | \n",
+ " \n",
+ " \n",
+ "  \n",
+ " Download notebook\n",
+ " \n",
+ " \n",
+ " Download notebook\n",
+ " \n",
+ " | \n",
+ "
\n"
+ ]
+ },
+ {
+ "attachments": {},
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "# Zero-Shot Segmentation with OWL-ViT, SAM, and FiftyOne\n",
+ "\n",
+ "This notebook walks you through how to add zero-shot instance segmentation masks to your dataset using [FiftyOne](https://voxel51.com/docs/fiftyone/). You will also see how to turn this into tracking data when applied to videos!\n",
+ "\n",
+ "In particular, you will learn how to:\n",
+ "- Extract PNGs from the frames of a video\n",
+ "- Run zero-shot object detection on the images\n",
+ "- Add segmentation masks to these detections\n",
+ "- Create tracks from those detections and masks"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ ""
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "For the purposes of illustration, we will use the `wildlife-watcher` dataset from Wildlife AI, which contains 7868 short video clips of a variety of animals.\n",
+ "\n",
+ "**Note**: You can also browse this dataset (with instance segmentation masks and tracking info) for free at [try.fiftyone.ai](https://try.fiftyone.ai/datasets/wildlife-watcher/samples)!"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "We will use the following libraries:\n",
+ "- [FiftyOne](https://github.com/voxel51/fiftyone) to organize our dataset and visualize the results\n",
+ "- [transformers](https://huggingface.co/docs/transformers/index) from Hugging Face to load and run inference with [OWL-ViT](https://huggingface.co/docs/transformers/model_doc/owlvit) for zero-shot object detection\n",
+ "- [Ultralytics](https://docs.ultralytics.com/) to run instance segmentation inference with bounding box prompts using Facebook's [Segment Anything Model](https://docs.ultralytics.com/models/sam/#sam-prediction-example)\n",
+ "\n",
+ "There are many ways to get these models. Additionally, there are other models that can be used for zero-shot object detection and instance segmentation. For example, [grounding DINO](https://github.com/IDEA-Research/GroundingDINO) is currently a state-of-the-art zero-shot object detection model.\n",
+ "\n",
+ "We will also use the headless version of [OpenCV](https://opencv.org/) to convert the videos to frame images.\n",
+ "\n",
+ "**Note**: For image-only datasets, FiftyOne [natively supports SAM](https://docs.voxel51.com/user_guide/model_zoo/models.html#segment-anything-vith-torch) as part of the [FiftyOne Model Zoo](https://docs.voxel51.com/user_guide/model_zoo/index.html#)!"
+ ]
+ },
+ {
+ "attachments": {},
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Setup"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Let's install the neccessary libraries:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "!pip install fiftyone transformers ultralytics opencv-python-headless"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "And then import all of the necessary packages:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "from glob import glob\n",
+ "import os\n",
+ "\n",
+ "import cv2\n",
+ "import fiftyone as fo\n",
+ "import numpy as np\n",
+ "from PIL import Image\n",
+ "from transformers import pipeline\n",
+ "from ultralytics import SAM"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Download the dataset from [this zip file](https://drive.google.com/file/d/1UfB3klvMUs9R7wlqUZ8Dlbdm1nF3Pu1a/view?usp=sharing) to a folder `taranaki` and unzip it."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Then load it into FiftyOne:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "dataset = fo.Dataset.from_dir(\n",
+ " \"taranaki\", \n",
+ " dataset_type=fo.types.FiftyOneVideoLabelsDataset\n",
+ " )"
+ ]
+ },
+ {
+ "attachments": {},
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Then we can give it a name and make it persistent:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 5,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "dataset.name = \"wildlife-watcher\"\n",
+ "dataset.persistent = True"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Then we convert the videos into sequences of images and save them in a folder. We will also use FiftyOne's `ensure_frames()` method to ensure that the frames are accessible on the videos, so we can add predictions to them."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "dataset.ensure_frames()\n",
+ "\n",
+ "mp4_files = glob(\"taranaki/data/*\")\n",
+ "\n",
+ "### Create PNGs for each frame\n",
+ "for mf in mp4_files:\n",
+ " subdir = os.path.basename(mf).split(\".\")[0]\n",
+ " frames_dir = f'taranaki/frames/{subdir}'\n",
+ " os.makedirs(frames_dir, exist_ok=True)\n",
+ " frame_number = 0\n",
+ " video = cv2.VideoCapture(mf)\n",
+ " while True:\n",
+ " success, frame = video.read()\n",
+ " if not success:\n",
+ " break\n",
+ " frame_path = os.path.join(frames_dir, f'frame_{frame_number}.png')\n",
+ " cv2.imwrite(frame_path, frame)\n",
+ " frame_number += 1\n",
+ " video.release() "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Add predictions to dataset"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Now that we have our frame PNGs, we will iterate through the samples in our dataset, adding zero-shot predictions."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "First, we define our detector. In this case, we know the *type* of animal we can expect to see in each image (from the `ground_truth` label on the frames), so we can use this as a text prompt for zero-shot detection with OWL-ViT:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "detector = pipeline(model=checkpoint, task=\"zero-shot-object-detection\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "We only want the bounding box of the highest confidence prediction, if there is one:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "def get_bounding_box(image, label):\n",
+ " predictions = detector(\n",
+ " image,\n",
+ " candidate_labels=[label],\n",
+ " )\n",
+ " \n",
+ " if len(predictions) == 0:\n",
+ " return None, None\n",
+ "\n",
+ " prediction = max(predictions, key=lambda x: x['score'])\n",
+ " score, box = prediction['score'], prediction['box']\n",
+ "\n",
+ " bounding_box = [box['xmin'], box['ymin'], box['xmax'], box['ymax']]\n",
+ " return bounding_box, score"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "We can then create an instance segmentation function which takes this bounding box as input, for a given input:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "sam_model = SAM('sam_l.pt')\n",
+ "\n",
+ "def run_box_sam_segmentation(image, bbox):\n",
+ " res = sam_model(image, bboxes=bbox)\n",
+ " mask = np.array(res[0].masks.data.cpu())[:, :][0]\n",
+ " return mask\n",
+ "\n",
+ "def generate_mask(image, label, width, height):\n",
+ " abs_bbox, score = get_bounding_box(Image.open(image), label)\n",
+ " \n",
+ " if not abs_bbox:\n",
+ " return None, None\n",
+ " (cmin, rmin, cmax, rmax) = abs_bbox\n",
+ " mask = run_box_sam_segmentation(image, abs_bbox)\n",
+ " bounding_box_mask = mask[rmin:rmax+1, cmin:cmax+1]\n",
+ "\n",
+ " rel_bbox = [cmin/width, rmin/height, (cmax-cmin)/width, (rmax-rmin)/height]\n",
+ " return bounding_box_mask, rel_bbox"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "The output bounding box from OWL-ViT is in absolute `xyxy` coordinates, and we use these absolute coordinates to truncate the full-image mask generated by SAM into an instance segmentation mask. At the end of the day, we convert the bounding box to relative `xywh` coordinates, which is the format accepted by FiftyOne Detection labels."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "To add mask to a sample, we loop over the frames in the video and add the generated mask, if there is one, to the frame:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "def add_masks_to_sample(sample, label):\n",
+ " subdir = sample.filename.split(\".\")[0]\n",
+ " frames_dir = f'taranaki/frames/{subdir}'\n",
+ " n_frames = len(sample.frames)\n",
+ " for i in range(n_frames-1):\n",
+ " frame = sample.frames[i+1]\n",
+ " frame_img = f\"{frames_dir}/frame_{i}.png\"\n",
+ " if not os.path.exists(frame_img):\n",
+ " continue\n",
+ " mask, bounding_box = generate_mask(\n",
+ " frame_img, \n",
+ " label, \n",
+ " sample.metadata.frame_width, \n",
+ " sample.metadata.frame_height\n",
+ " )\n",
+ " if mask is None:\n",
+ " continue\n",
+ " frame[\"sam_track\"] = fo.Detections(\n",
+ " detections = [\n",
+ " fo.Detection(\n",
+ " label = label,\n",
+ " bounding_box = bounding_box,\n",
+ " mask = mask,\n",
+ " index = 1\n",
+ " )\n",
+ " ]\n",
+ " )\n",
+ " sample.save()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Note that here we are setting `index=1` for each detection. This is because we only expect to see a single animal in each video, so we can say with decent certainty that all of the detections correspond to the same animal. This index will be used to associate detections with tracks, which you can extract with `to_trajectories()`!"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Now all that is left is to loop over samples in the dataset:"
+ ]
+ },
+ {
+ "attachments": {},
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Then unzip these zip files:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 2,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "def add_sam_tracks(dataset):\n",
+ " for sample in dataset[100:].iter_samples(autosave=True, progress=True):\n",
+ " if \"ground_truth\" not in sample.frames[1]:\n",
+ " continue\n",
+ " if sample.frames[1].ground_truth is None:\n",
+ " continue\n",
+ " label = sample.frames[1].ground_truth.label\n",
+ " add_masks_to_sample(sample, label)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "session = fo.launch_app(dataset)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "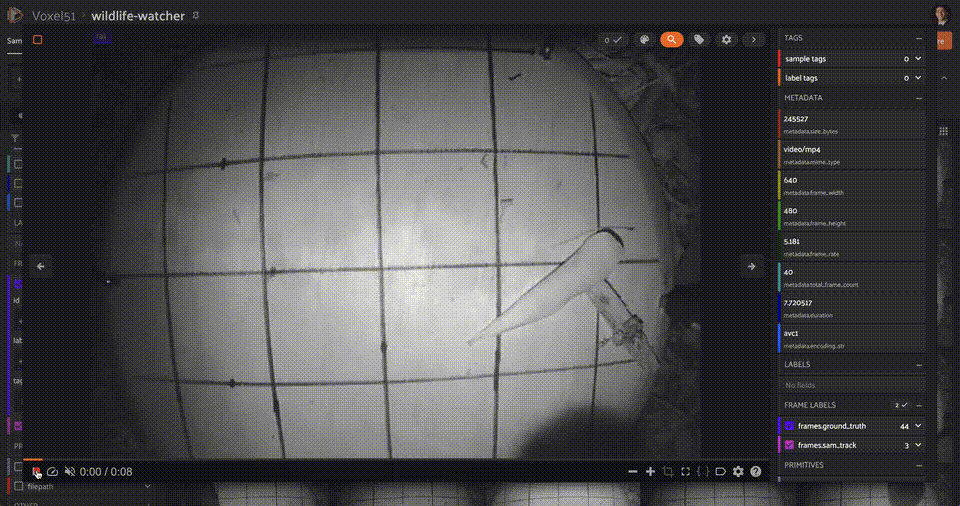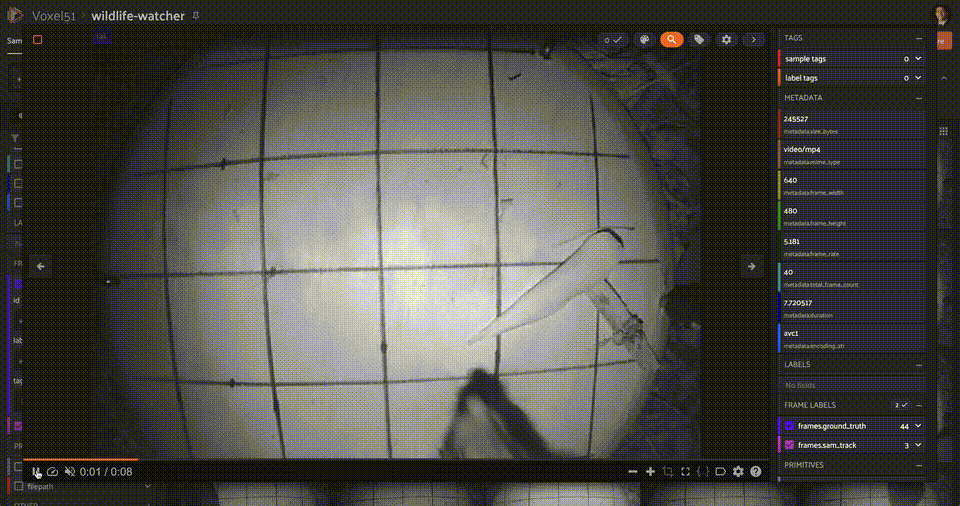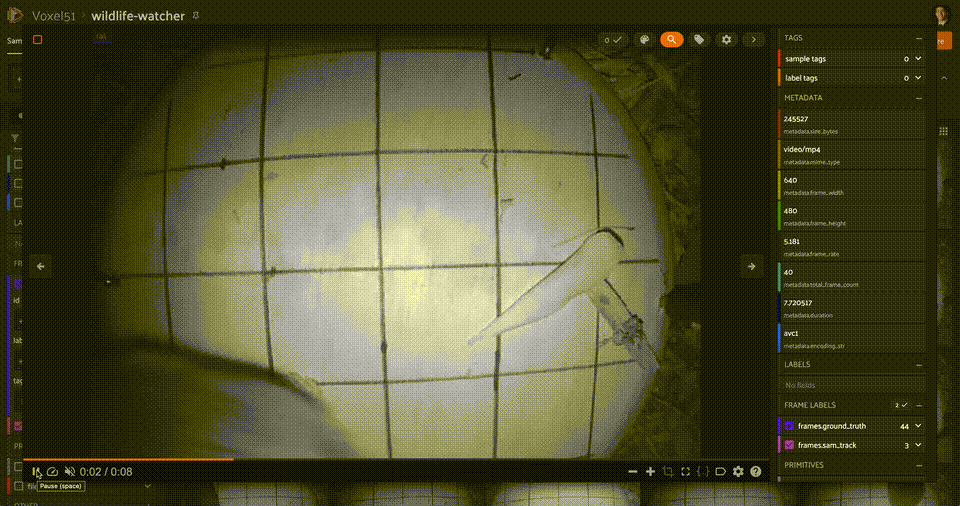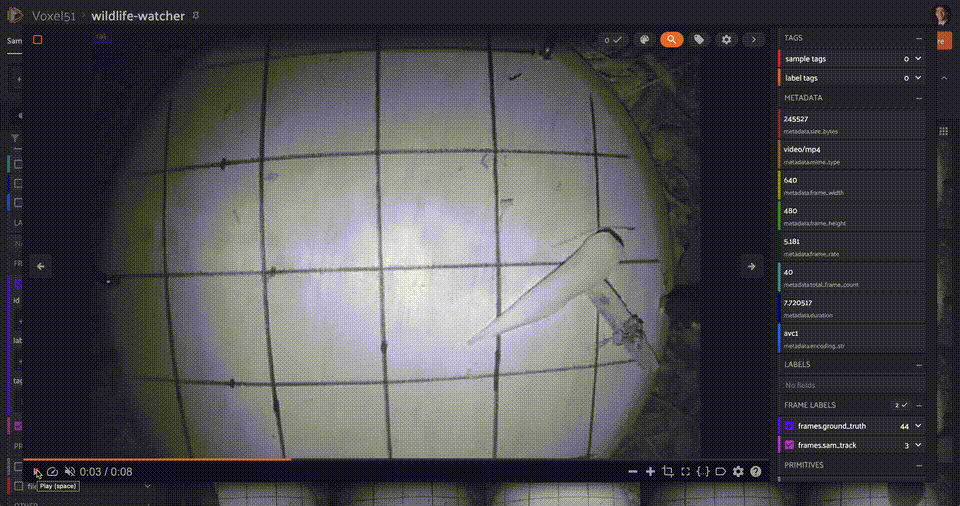"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "One of the main takeaways from this experiment is that zero-shot computer vision pipelines are inherently limited. The model is not able to generalize to unseen classes, and the performance on seen classes is not as good as a model trained on those classes. In this case, there were very few detections for small objects, as well as objects not seen from a frontal view, or objects which were occluded or truncated!"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": []
+ }
+ ],
+ "metadata": {
+ "kernelspec": {
+ "display_name": "Python 3",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.9.16"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 4
+}
diff --git a/index.yaml b/index.yaml
index 9ce8497..405a1f1 100644
--- a/index.yaml
+++ b/index.yaml
@@ -83,3 +83,6 @@ examples:
- title: "CLI Tips & Tricks"
path: "examples/Tips_and_Tricks_CLI.ipynb"
description: "Use FiftyOne's Command Line Interface to expedite your workflows"
+ - title: "zero_shot_instance_segmentation"
+ path: "examples/zero_shot_instance_segmentation.ipynb"
+ description: "Combine zero-shot detection plus segmentation and tracking with OWL-ViT, SAM, and FiftyOne"