We love scraping, don't we? But sometimes, we face Cloudflare protection. This script is designed to bypass the Cloudflare protection on websites, allowing you to interact with them programmatically.

If you’re looking for an automation browser tool designed to bypass website bot detection systems, I highly recommend the Scrapeless Scraping Browser. This cloud-based browser platform features advanced stealth technology and powerful anti-blocking capabilities, making it easy to handle dynamic websites, anti-bot mechanisms, and CAPTCHA challenges. With a built-in free CAPTCHA solver, it is perfectly suited for web scraping, automated testing, and data collection—especially in environments with complex anti-bot defenses.
Key Features:
- Built-in Free CAPTCHA solver: Instantly solves reCAPTCHA, Cloudflare Turnstile/Challenge, AWS WAF, DataDome, and more.
- High-concurrency scraping: Run 50 to 1000+ browser instances per task within seconds, with no server resource limits.
- Human-like browsing environment: Dynamic fingerprint spoofing and real user behavior simulation, powered by the Scrapeless Chromium engine for advanced stealth.
- Headless mode support: Compatible with both headful and headless browsers, adapting to diverse anti-scraping strategies.
- 70M+ residential IP proxies: Global coverage with geolocation targeting and automatic IP rotation.
- Low operating costs: Proxy usage costs only $1.26 to $1.80 per GB.
- Plug-and-play integration: Fully compatible with Puppeteer, Playwright, Python, and Node.js for seamless setup.
Scrapeless is an all-in-one, enterprise-grade, and highly scalable data scraping solution built for developers and businesses. Beyond the Scraping Browser, it also offers a Scraping API, Deep SerpAPI, and robust proxy services.
👉Learn more: Scrapeless Scraping Browser Playground | Scrapeless Scraping Browser Documentation
If you use Selenium, you may have noticed that it is not possible to bypass Cloudflare protection with it. Even you click the "I'm not a robot" button, you will still be stuck in the "Checking your browser before accessing" page. This is because Cloudflare protection is able to detect the automation tools and block them, which puts the webdriver infinitely in the "Checking your browser before accessing" page.
As you realize, the script uses the DrissionPage, which is a controller for the browser itself. This way, the browser is not detected as a webdriver and the Cloudflare protection is bypassed.
You can install the required packages by running the following command:
pip install -r requirements.txt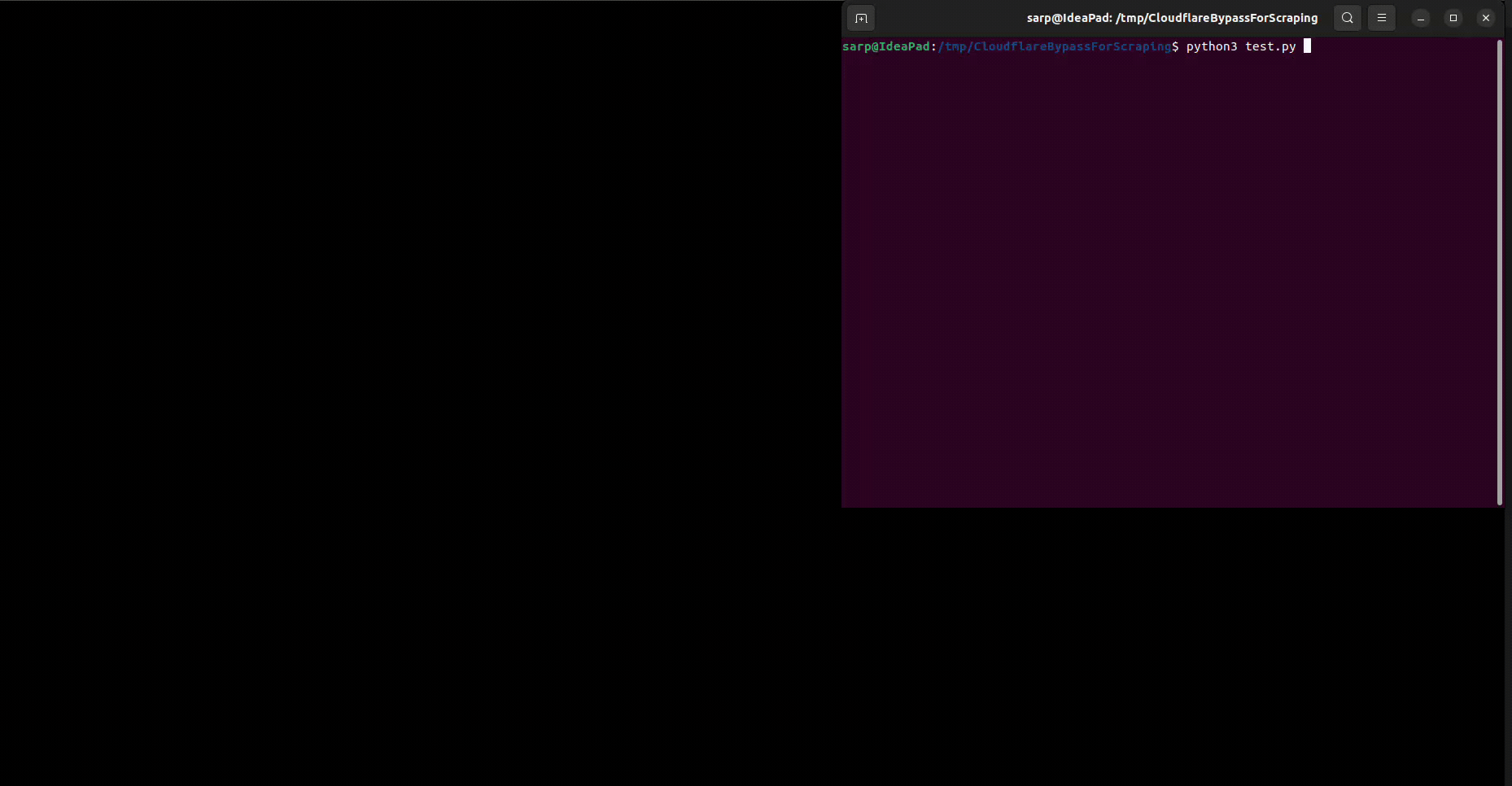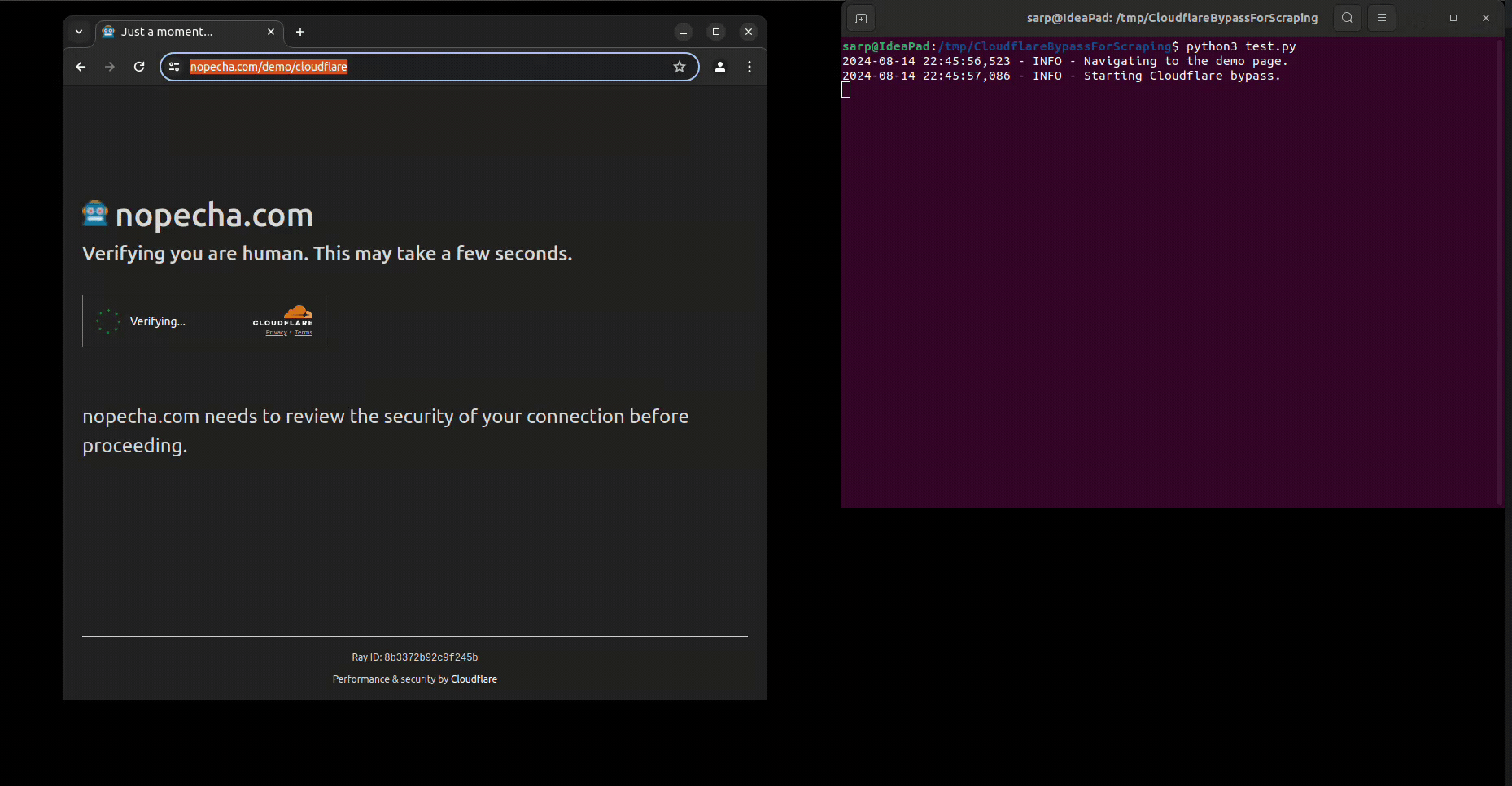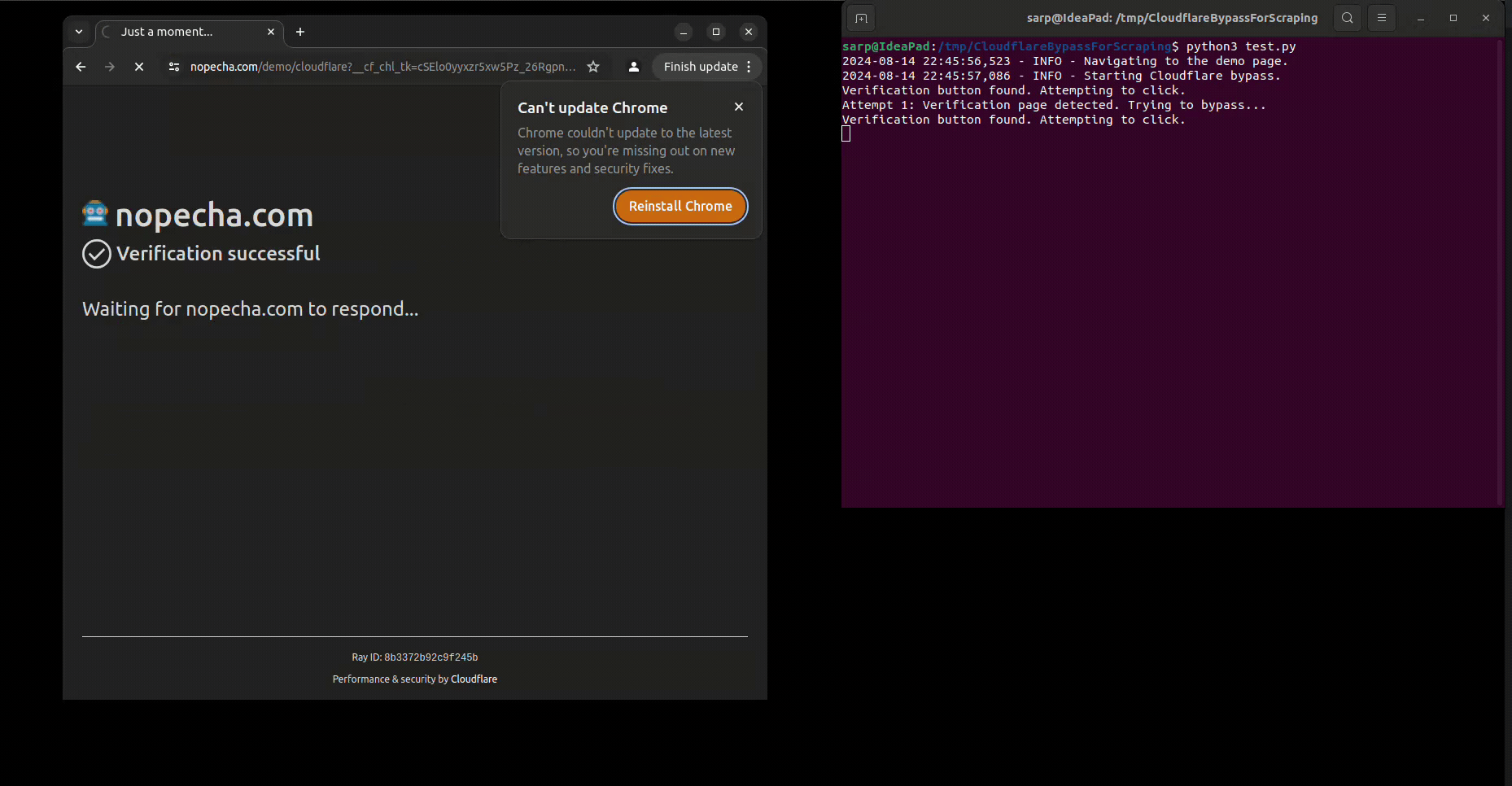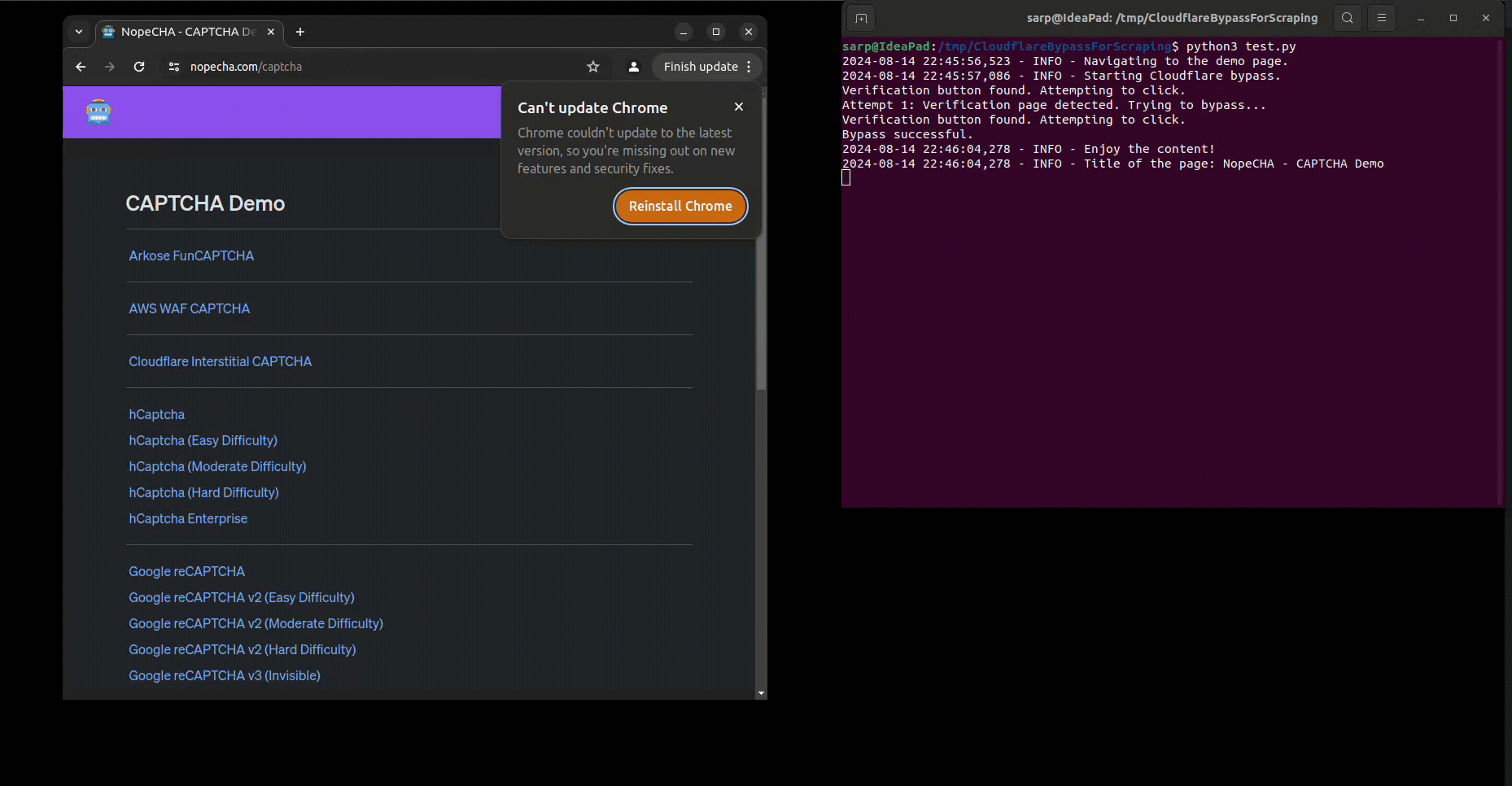
Create a new instance of the CloudflareBypass class and call the bypass method when you need to bypass the Cloudflare protection.
from CloudflareBypasser import CloudflareBypasser
from DrissionPage import ChromiumPage
driver = ChromiumPage()
driver.get('https://nopecha.com/demo/cloudflare')
cf_bypasser = CloudflareBypasser(driver)
cf_bypasser.bypass()You can run the test script to see how it works:
python test.pyRecently, @frederik-uni has introduced a new feature called "Server Mode". This feature allows you to bypass the Cloudflare protection remotely, either you can get the cookies or the HTML content of the website.
You can install the required packages by running the following command:
pip install -r server_requirements.txtStart the server by running the following command:
python server.pyTwo endpoints are available:
/cookies?url=<URL>&retries=<>&proxy=<>: This endpoint returns the cookies of the website (including the Cloudflare cookies)./html?url=<URL>&retries=<>&proxy=<>: This endpoint returns the HTML content of the website.
Send a GET request to the desired endpoint with the URL of the website you want to bypass the Cloudflare protection.
sarp@IdeaPad:~/$ curl http://localhost:8000/cookies?url=https://nopecha.com/demo/cloudflare
{"cookies":{"cf_clearance":"SJHuYhHrTZpXDUe8iMuzEUpJxocmOW8ougQVS0.aK5g-1723665177-1.0.1.1-5_NOoP19LQZw4TQ4BLwJmtrXBoX8JbKF5ZqsAOxRNOnW2rmDUwv4hQ7BztnsOfB9DQ06xR5hR_hsg3n8xteUCw"},"user_agent":"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36"}You can also run the server in a Docker container. Thanks to @gandrunx for Dockerizing the server.
First, build the Docker image:
docker build -t cloudflare-bypass .Then, run the Docker container:
docker run -p 8000:8000 cloudflare-bypassAlternatively, you can skip docker build step, and run the container using pre-build image:
docker run -p 8000:8000 ghcr.io/sarperavci/cloudflarebypassforscraping:latestHere are some example projects that utilize the CloudflareBypasser Server:
- Calibre Web Automated Book Downloader - A tool to download books from calibre web.
- Kick Unofficial API - A tool to interact with the Kick.com, download videos, send messages, etc.