A powerful Express.js proxy server that connects Ollama with Helicone for advanced LLM observability and monitoring of your local Llama requests.
This proxy server acts as a bridge between your Ollama instance and Helicone's powerful observability platform. It enables you to monitor, track, and analyze all your Ollama LLM interactions while being able to run your local Llama models.
You use this proxy server as the endpoint for your LLM requests, which takes charge of logging the requests to Helicone and serving the responses from your local Ollama instance.
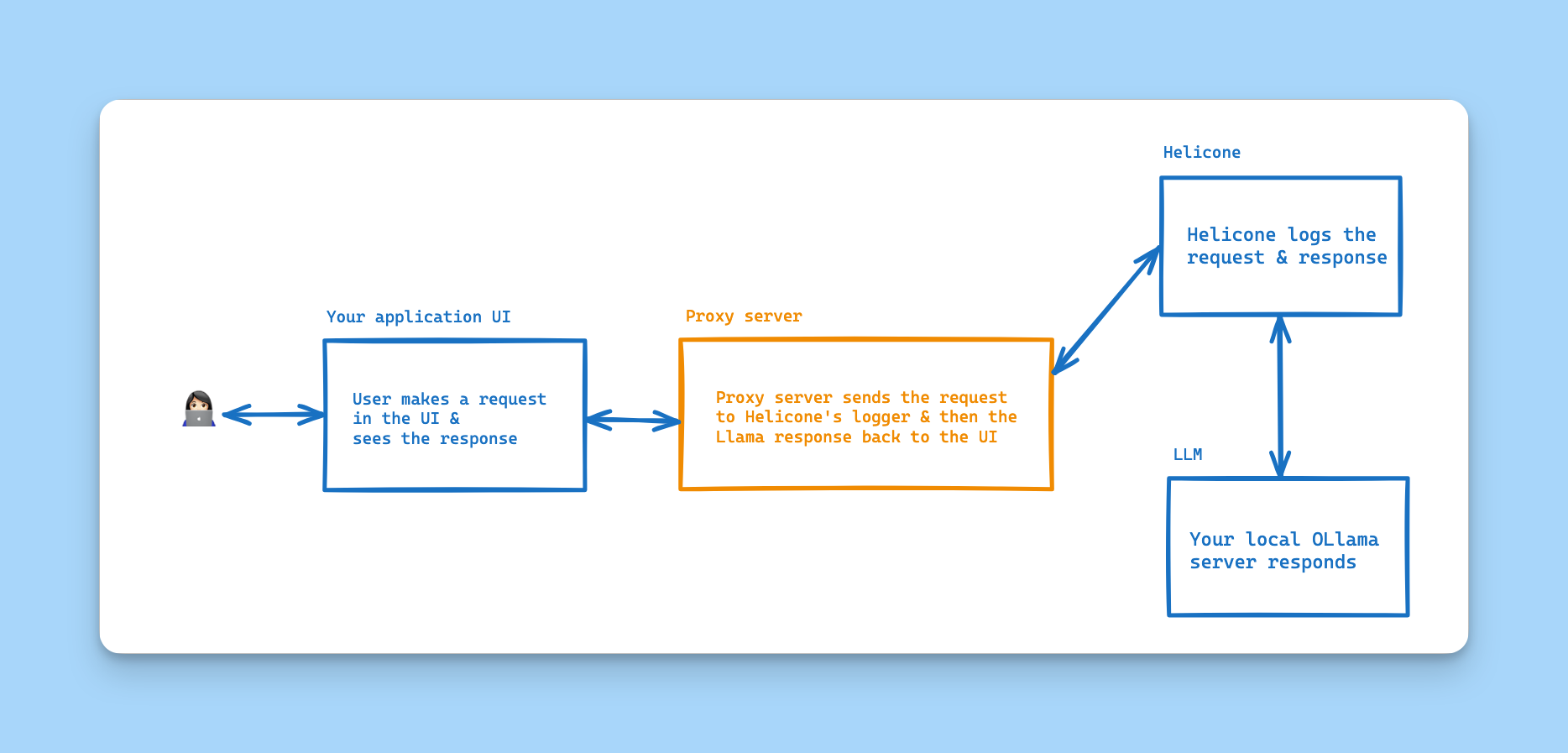
- Seamless integration between Ollama and Helicone
- Full support for Ollama's chat and generation endpoints
- Automatic request/response logging
- Version and model tag checking endpoints
- Node.js (14.x or higher)
- Ollama installed locally
- Helicone API key
-
Sign up for a free account at Helicone and get your API key from the dashboard settings.
-
Create a
.envfile in your project root:
HELICONE_API_KEY=your_helicone_api_key_here- Install dependencies:
npm install- Start your local Ollama server:
ollama serveThis command starts the Ollama server locally on port 11434. The server must be running for the proxy to work. You can also determine the specific model you want to use by running ollama list to see all the models available.
- Start the proxy server:
npm startThe server will start on port 3100 by default.
To verify that everything is working correctly, you can send a test request:
curl -X POST http://localhost:3100/api/chat \
-H "Content-Type: application/json" \
-d '{"model":"llama2","messages":[{"role":"user","content":"Hello"}]}'After running this command:
- You should see a response from the Ollama model being served from your local machine in your terminal
- Log into your Helicone dashboard to see the request logged with all its details in the Requests view.
- The dashboard will show metrics like response time, token usage, and request status, etc.
If you can see the request in your Helicone dashboard, congratulations! Your setup is working correctly.
POST http://localhost:3100/api/chatExample request:
{
"model": "llama2",
"messages": [
{
"role": "user",
"content": "Hello, how are you?"
}
]
}POST http://localhost:3100/api/generateExample request:
{
"model": "llama2",
"prompt": "Write a story about a space cat"
}GET /api/version- Get Ollama versionGET /api/tags- List available models
This proxy automatically integrates with Helicone, a powerful LLM observability platform that provides:
- Detailed request/response logging
- Cost tracking and analytics
- Latency monitoring
- User behavior analytics
- Custom property tracking
- Advanced filtering and search capabilities
By using Helicone, you gain unprecedented visibility into your LLM operations, helping you:
- Optimize costs and performance
- Debug issues faster
- Understand usage patterns
- Make data-driven decisions about your LLM implementation
The proxy server handles both streaming and non-streaming responses from Ollama, ensuring compatibility with various client implementations while maintaining detailed logging through Helicone.
MIT Open Source
Contributions are welcome! Please feel free to submit a Pull Request.